主页 > 官网imtoken安卓版 > 区块链行业专题报告:隐私计算深度解析
区块链行业专题报告:隐私计算深度解析
一、隐私计算融合多领域技术,实现“数据可用、不可见”
1.1、隐私计算可以形成保护数据的前提未来数据价值挖掘的实现
数据是数字经济时代的一种新型生产要素,其重要性已被世界各国政府充分重视。聚合多维海量数据,挖掘数据内在价值,实现数据价值多元化,已成为全球各产业组织的战略重点。隐私计算是指在提供隐私保护的前提下,实现数据价值挖掘的技术系统。面对数据计算参与者或其他潜在的信息窃贼,隐私计算可以实现对处于加密状态或隐蔽(不透明)状态的数据进行计算,实现了对每个参与者信息的保护。隐私计算在保证数据安全的基础上实现数据的流动和共享,真正实现“数据可用性是无形的”。
隐私计算技术是人工智能、密码学、区块链、数据科学和计算芯片的交集。私有计算以现代密码学为核心,与计算机体系结构、计算复杂性理论、信息论、统计学、抽象代数、数论等理论共同发展。
隐私计算保障的目标涵盖数据应用的方方面面,包括:
1.隐私计算保证了数据端数据静态存储的风险;
2.隐私计算保证了数据从数据方到计算方的传输风险;
3.隐私计算保证了计算方计算时数据的隐私风险;
4.隐私计算保证了计算方计算后数据的隐私风险;
5.隐私计算保证了计算方法中计算结果的静态存储风险;
6.隐私计算保证了计算结果从计算方法到结果方的传输风险;
7.隐私计算保证了计算结果方的静态存储风险。
1.2、隐私计算是由大数据融合应用和隐私保护的双重需求驱动的
根据中国信息通信研究院的数据,全球数据量正处于指数增长阶段。 2020年全球数据生成量约为48ZB。未来,全球数据生成量将迎来爆发式增长。 2035年全球数据生成量预计将超过2000ZB。
一方面,大数据只有被使用后才能产生价值。现阶段,全球大数据的“数据孤岛效应”显着。数据之间缺乏相关性,很多数据库互不兼容。此外,企业对数据信息保护的意识逐渐增强,降低数据隔离的难度也逐渐增加。但是,企业和组织通过数据流与行业上下游业务伙伴实现深度合作、提高决策能力、获得竞争优势的需求仍将长期存在。隐私计算从技术角度可以实现“不将原始数据存储在数据库中的完整数据价值流通”的目标。
另一方面,大数据的应用面临越来越多的合规风险。根据我国《网络安全法》和《民法典》的规定,数据处理者在处理数据时应当公开收集和使用规则,并征得用户同意。近年来,我国数据安全管理规范化程度逐步提高:2019年9月,工信部在《工业大数据发展指导意见》中表示,将积极推进多方安全计算工业领域的基地; 2020年12月,国家发展改革委、国家互联网信息办公室、工业和信息化部、能源局联合印发《关于加快建设国家综合大数据中心协同创新体系的指导意见》 隐私计算可以防止数据信息泄露,缓解信任危机,实现大数据应用过程的合规性。
政策驱动的隐私计算发展空间。中国隐私计算相关法律和政策催生了对隐私计算的需求区块链存储数据太大,鼓励了隐私计算相关技术的研发和应用。中国通过出台相关政策法规,推动建立公共隐私保护制度,维护数据权利主体的合法权益。同时,通过政策法规的逐步完善,不断完善数据应用和安全保护体系的顶层设计,逐步明确数据安全和隐私保护的合规要求,隐私的应用场景计算有望进一步扩大。 (报告来源:未来智库)
二、 安全多方计算、联邦学习和机密计算是隐私计算的主要技术发展路径。实施进度比较先进
隐私计算处于技术多路径探索阶段:隐私计算仍处于技术探索阶段。目前隐私计算的主要技术路径包括多方安全计算、联邦学习、机密计算(包括可信执行环境)、差分隐私(包括局部差分隐私)、同态加密、零知识证明等。商业场景分析,安全多方计算、联邦学习和机密计算的商业进展比较先进,零知识证明主要应用于区块链场景。
2.1、安全多方计算 (SMPC)
安全多方计算是由中国科学院院士姚启智于 1982 年提出的。一组相互不信任的各方,每个持有秘密数据,在计算给定函数的问题上进行协作。安全多方计算是为了保证多个参与者获得正确的计算结果,同时不能获取计算结果以外的任何信息,从而保证各方数据的安全和隐私。安全多方计算技术包括秘密共享、不经意传输、乱码电路、私有集合交集、隐私信息检索等关键计算协议。安全多方技术正在不断提高计算效率,降低实现设计的复杂性。基于以上特点,隐私计算的优缺点如下:
优势:安全的多方计算允许参与者(数据所有者)对其数据拥有绝对的控制权
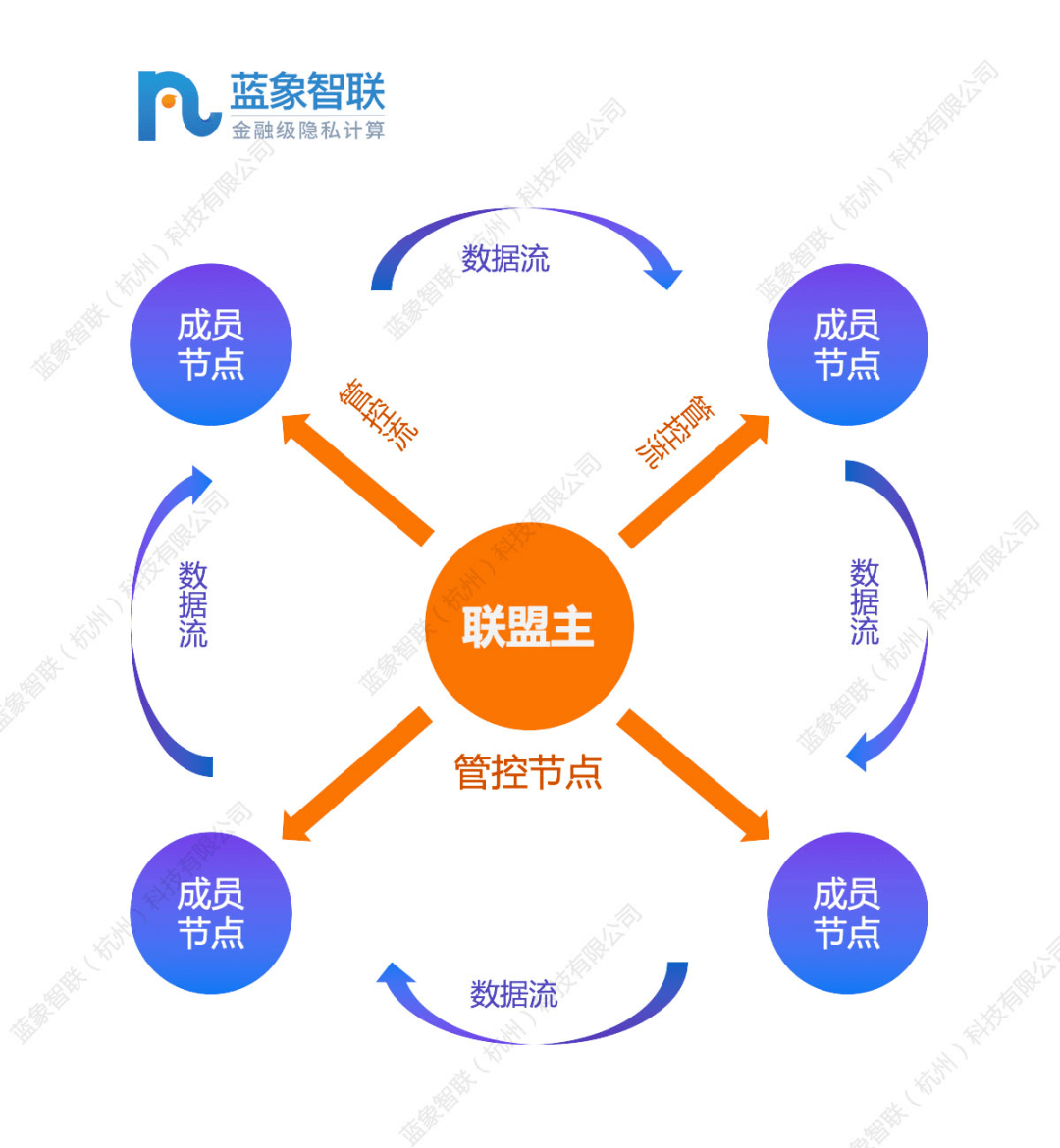
缺点:安全多方计算计算工作量大,需要强大的硬件性能支持。安全多方技术受到网络带宽、时延等因素的制约。安全多方计算通用性有限,需要针对特定问题和场景设计专用协议。
2.2、联邦学习 (FL)
联邦学习(Federated Learning)于2016年由谷歌首次提出,用于解决Android手机终端用户在本地更新模型的问题。其设计目标是保证大数据交换过程中的信息安全,保护终端数据和个人数据的隐私,确保合法合规。在计算节点之间进行高效的机器学习。可用于联邦学习的机器学习算法不仅限于神经网络,还包括随机森林等重要算法。
针对不同的数据集,联邦学习可以分为横向联邦学习(Horizontal Federated Learning,HFL)、纵向联邦学习(Vertical Federated Learning,VFL)和联邦迁移学习(FTL):
横向联邦学习主要是指每个参与者的数据集特征重叠较大,但样本重叠较小的场景。横向联邦学习将数据集按照横向(即用户维度)进行划分,取出两个用户特征相同但用户不同的数据进行训练。 2016年,谷歌提出了Android手机模型更新的数据联合建模解决方案:当单个用户使用Android手机时,模型参数在本地不断更新,并上传到Android云端,使每个数据具有相同的特征维度可以更新。拥有方构建联邦模型。
垂直联邦学习主要是指每个参与者的数据集特征集重叠较小,但样本重叠较大的场景。纵向联邦学习将数据集按照纵向(即特征维度)进行划分,取出部分用户相同但用户特征不完全相同的数据进行训练。在这个阶段,逻辑回归模型、树结构模型、神经网络模型等许多机器学习模型已经逐渐被证明能够建立在垂直联邦学习系统之上。
联邦迁移学习主要是指每个参与者的样本和特征重叠度极低,模型训练时每个数据集的样本空间和特征空间重叠度很小的场景。 联邦迁移学习主要是为了解决单边数据规模小、标注样本少的问题,从而提高模型的效果。
2.3、机密计算(CC)/可信执行环境(TEE)
机密计算是一种云计算技术,可在处理过程中将敏感数据隔离在受保护的 CPU 区域中。正在处理的数据和用于处理该数据的技术只能通过授权的编程代码访问,并且对任何人或任何其他人(包括云提供商)都是不可见和不可知的。机密计算是一种基于硬件可信执行环境实现数据应用保护的技术。 2019年8月,Linux基金会宣布成立机密计算联盟,该联盟由埃森哲、蚂蚁集团、ARM、谷歌、Facebook、华为、微软、红帽等众多巨头组成。该联盟致力于保护云服务和硬件生态系统。数据应用程序的安全性。
机密计算对隐私计算具有重要意义,其主要优势包括:

机密计算还可以保护使用中的敏感数据,并将云计算的优势扩展到敏感工作负载。
机密计算可以有效保护知识产权。机密计算不仅用于数据保护,可信执行环境 TEE 还可用于保护专有业务逻辑、分析功能、机器学习算法或整个应用程序。
机密计算与合作伙伴安全地合作开发新的云解决方案。
机密计算可以消除客户在选择云提供商时的顾虑。当云提供商提供其他竞争性业务服务时,机密计算可以降低泄露风险。
ARM和Intel在机密计算技术上处于领先地位,ARM TrustZone和Intel SGX是机密计算领域相对成熟的两项技术。 ARM TrustZone 将系统的硬件和软件资源划分为两个执行环境,以保证整个系统的安全。 Intel SGX允许应用程序实现一个Enclave容器,在应用程序的地址空间划分一个保护区,将合法软件的安全操作封装在Enclave中,并为容器内的代码和数据提供机密性和完整性保护,外部没有软件容器可以访问 enclave 内的数据。
2.4、 差分隐私(DP)
差分隐私 (DP) DP) 是密码学中的一种方法,旨在提供一种方法,在从统计数据库中查询时最大限度地提高数据查询的准确性,同时最大限度地减少识别其记录的机会。差分隐私基于严格的数学理论。通过在计算结果中加入噪声,确保供应商无法根据输出差异推断个人敏感信息,从而在不损害个人隐私的情况下最大限度地利用数据资源。差分隐私技术还对隐私保护进行了严格的定义,并提供了量化的评价方法,严格证明了隐私保护的水平。
差分隐私通过添加噪声来保护隐私,这可能会影响模型的数据可用性和准确性。过多的噪声会严重损害数据统计的可用性和准确性,因此差分隐私无法在人脸识别、金融风险剂量等领域进行大规模的商业应用。现阶段差分隐私技术发展的重点是降低噪声对准确性的影响。
本地差分隐私:传统差分隐私将原始数据集中在一个数据中心,然后对数据中心的数据应用差分隐私算法,然后将其发布到外界。这种方法也称为中心化差分隐私。隐私(集中式差分隐私,CDP)。但是中心化的差分隐私需要一个可信的第三方数据收集器,即保证收集到的数据不会被窃取和泄露。但在实际应用中,可信的第三方数据采集器却很难找到。为此,提出了局部差分隐私(LDP)方案。本地差分隐私基于不可信第三方的前提,将数据隐私的工作移交给每个用户,用户对个人数据进行处理和保护,大大降低了隐私泄露的可能性。本地差分隐私已被谷歌、苹果、微软等互联网巨头广泛使用。但与传统的中心化差分隐私方案相比,局部评分隐私方案对数据的噪声增加较多,面向数据统计时数据的可用性较低。
2.5、同态加密(HE)

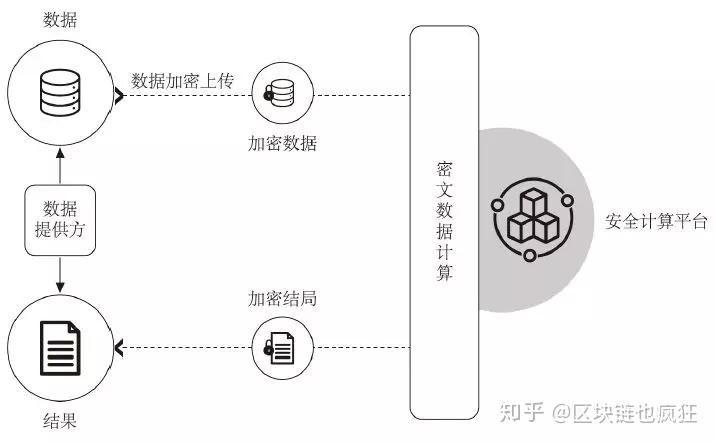
同态加密(HE) 加密(HE)系统是一种加密形式,它允许人们对密文进行某种形式的代数运算,得到仍然加密的结果,解密得到的结果与对明文进行相同操作的结果。换言之,该技术可以对加密材料进行检索、比较等操作,从而获得正确的结果,而无需在整个过程中对材料进行解密。现阶段同态加密的发展瓶颈是算法要求高,同态加密效率低。因此,同态加密暂时不能用于大规模业务。
部分同态加密:目前同态加密的实现大多是通过非对称加密算法,即所有知道公钥的参与者都可以加密并进行密文计算,但只有私钥的拥有者可以解密。同态加密系统可以系统地分为四类:部分同态、近似同态、有限级数全同态和完全同态。其中,部分同态、近似同态和有限级数全同态又可分为部分同态加密方案。某种程度的同态加密(SHE)只能支持有限深度的密文计算。例如,Paillier 支持密文之间的加法,但不支持密文之间的乘法。 BGN 支持密文和密文之间的无限加法。一个乘法运算。由于部分同态加密的局限性,一般不用于独立构建隐私计算方案,而部分同态加密多用于联邦学习方案中的安全性增强。
完全同态加密(FHE)系统对计算方法没有任何限制。用户可以任意组合密文,形成新的密文,无需密钥。并且新的密文可以用任何计算复杂度恢复为原始文本。支持近似十进制计算的CKKS方案帮助提升了全同态加密的计算性能,但全同态加密的计算能力要求仍然极高,现阶段尚未大规模商用。 (报告来源:未来智库)
三、隐私计算的商业用途
隐私计算涵盖数据生产,面向隐私的计算系统和存储、计算、应用全过程的技术可以在保证原始数据安全和隐私的同时,实现对数据的计算和分析。由于隐私计算在多数据流的融合中具有显着的保护隐私和安全的作用,隐私计算在政务、金融、医疗、交通、营销等众多行业有着广泛的应用场景。
金融:金融与数字技术的融合不断深化,跨领域的融合应用不断加强,数据的共享开放正在成为金融行业的新趋势。为了保护金融用户和金融企业的隐私和安全,隐私计算在金融领域有着广阔的应用前景,可以在信用风险评估、供应链金融、保险、精准营销、多方利益相关者等方面发挥重要作用借贷。一般情况下,单个金融机构自身数据量少,建模样本数不足。多机构联合建模会涉及数据安全风险。通过联邦学习建模,可以在不泄露数据的情况下整合和应用来自多个机构的数据,提高模型的准确性。而且,当金融机构获得新的相关数据时,可以及时更新模型,让其他金融机构也能快速具备预测识别能力。
政务:中国正在积极推动政企数据融合,发展数据生产要素。地方政府还建立了政务数据平台和大数据中心。中国政府拥有大量的社保数据、公积金数据、税收数据、交通数据等,但这些数据属于不同的部门或地区,存在很强的“数据孤岛”现象。这些数据的整合和应用需要极其繁琐的审批程序。此外,这些数据涉及公民隐私,很难有效利用这些数据的价值。隐私计算与其他技术相结合,可以有效保护各部门数据,部分解决“数据孤岛”问题,提升政务数据的使用价值。
医疗:在医疗健康行业,人工智能和大数据的应用主要是对大规模病例和疾病数据进行深度挖掘,通过建立机器来提升医学研究和疾病推理学习和模型训练。效率,促进整个医疗服务精准度的提高。但医疗数据对患者极为敏感,现阶段建立全国统一的医疗信息系统成本过高。隐私计算为这个痛点提供了解决方案。通过隐私计算对不同数据源进行横向和纵向联合建模,保障各方医疗数据的安全。医疗机构可以在本地建立模型,然后通过SMPC等技术与其他医疗机构更新模型参数,从而以最安全、最高效的方式提高模型的诊断能力和准确性。
交通:智能交通系统的建立依赖于定位数据、个人数据、政务数据、道路数据等多种数据的整合。由于管理所有权的范围广泛且分散,交通数据很容易形成数据孤岛。安全多方计算、零知识证明等私有计算数据可以帮助交通数据有效打破信息壁垒。隐私计算技术可以利用视频、位置、交通等多部门数据,研判公共安全防控和突发事件,合理配置资源,提高应急处置能力和安全防范能力。隐私计算还可以结合多个部门的数据,研究和判断道路交通状况,实现车辆路线的优化规划,减少交通拥堵。
营销:联合学习技术可以帮助营销联合建模,提高营销效果和用户体验。在一个营销场景中,数据方和营销方都拥有一部分数据,数据方拥有用户画像等流量数据,营销方拥有营销场景数据,但双方都不想分享这部分数据。核心数据。联邦学习可以在输出建模结果的同时保护双方数据安全,有效提高营销模型的准确性,提升营销效率。
隐私计算尚未广泛商业化,商业模式仍处于探索阶段。隐私计算服务分为硬件、软件和全栈服务三类。其中,纯硬件服务在隐私计算服务中占比极低,软件/全栈服务的商业模式可以模仿主流算法/软件成熟的商业模式。
四、隐私计算玩家现状:MPC和联邦学习成为主要技术路径
隐私计算的主要参与者包括互联网公司和初创企业,MPC和联邦学习成为主要技术路径主要技术路径,TEE和区块链是次要技术路径;现阶段,金融是隐私计算的主要应用场景,部分企业围绕政务、营销、医疗等垂直场景打造解决方案。
五、思考:私有计算发展预测
多种技术路径正在共同发展。现阶段,MPC、TEE、联邦学习是三大支柱。隐私计算的底层技术有很多可供选择,而隐私计算的实现可能需要多种技术的融合。现阶段,MPC、TEE和联邦学习这三项技术正在引领商业化进程,这种技术趋势在短期内仍将持续。从长远来看,MPC和联邦学习需要私有计算提供商长期积累有效数据并迭代优化算法,而TEE则需要在此基础上优化底层芯片设计。总的来说,TEE对供应商的软硬件全栈能力要求极高。现阶段,只有中国厂商才能做到这一点。出于成本考虑,MPC和联邦学习的应用比例可能会增加。
在私有计算应用中同态加密和差分隐私的实现很慢。同态加密需要极高的算力资源。现阶段常规GPU芯片无法满足同态加密所需的算力,同态加密的技术演进将不断提升对算力的需求。因此,同态加密的商用可能需要底层根据同态加密算法设计ASIC等专用芯片。另一方面,差分隐私的准确性不高,在隐私计算中长期独立应用前景狭窄,但可以成为辅助数据安全和数据加密的增强应用。
企业很难建立具有单一竞争优势的私有计算生态系统,算法和数据缺一不可。隐私计算解决方案高度依赖其底层技术的成熟度。然而,仅仅依靠隐私计算的底层技术,企业无法为用户提供有效的服务。用户的需求往往是针对数据需求极度定制化和专门化的,因此隐私计算提供商需要为用户提供有效的脱敏数据。另一方面,在没有大量有效数据的情况下,隐私计算的算法演进速度和优化程度也会受到影响。因此,私有计算生态系统的建立需要供应商掌握优秀的算法和丰富的数据资源。互联网巨头、深耕垂直场景的初创企业、行业龙头企业拥有这两种资源,为他们成功部署隐私计算提供了可能。
隐私计算的通用性受限于底层技术,垂直场景算法具有高度的辨别力。隐私计算底层技术是通用的,底层平台的建立是可能的。纵观隐私计算的发展生态,主要参与者可以分为三类:互联网公司、垂直行业公司和初创公司。互联网巨头最有发展通用底层平台的潜力。未来生态可能会在这个底层平台的基础上,进一步开发针对不同场景的垂直解决方案。
隐私计算技术开源程度有限,优先布局的厂商占据优势。现阶段,国内只有腾讯、微众银行、百度、字节跳动、矩阵元等为私有计算服务商开源。互联网巨头腾讯的开源侧重于底层框架,而百度的开源也采用渐进式开放的形式。总体而言,隐私计算的源码开放性较低,优先布局的厂商在算法端具有优势。后期入局的厂商也可以利用自身的数据和生态资源,快速升级算法。生态资源更丰富、流量入口更多的后入者成功概率相对较高。在未来的发展趋势中还有另一种可能区块链存储数据太大,即当隐私计算的开放性增强或领先供应商建立隐私计算的底层平台时,一些有人才资源的初创公司会基于隐私计算开发专门的垂直解决方案。底层平台,占用一定空间。市场份额。
(本文仅供参考,不代表我们的任何投资建议,相关信息请以报告原文为准。)
选定的报告来源:[未来智库]。未来智库-官方网站